
El contenido duplicado, sin lugar a dudas, es algo que puede lastrar el posicionamiento SEO de nuestro sitio Web o eCommerce. Y, a pesar de ello, éste es uno de los errores menos optimizados o tenidos en cuenta por la mayoría de nosotros.
En la actualidad, este problema es motivo más que suficiente para que muchas de las páginas de tu sitio, quizás aquellas que ya tenías medianamente posicionadas, vayan con el tiempo desapareciendo de los primeros puestos de las búsquedas.
¿Por qué? Simple, porque si tenemos en cuenta que Google depura de forma constante la SERP, para así mostrar resultados cada vez de más calidad y relevancia para sus usuarios, no nos debería sorpréndenos que el contenido duplicado sea mal visto por él.
A caso a ti, en una de tus búsquedas, te gustaría encontrarte literalmente con el mismo texto e información en casi cada uno de los resultados de las primeras páginas de Google.
Me imagino que “no”. Esa situación no te gustaría a ti, ni creo que le guste a nadie. Pero, por suerte, haya sido voluntario o involuntario, estos errores tienen una solución.
En este artículo vamos a conocer cómo detectar el contenido duplicado (gracias a algunas de las herramientas SEO que yo mismo utilizo) y a aprender a darle las soluciones más efectivas según cada caso.
Pero antes, como habitualmente hago en todas mis guías y tutoriales, me gustaría primero ponerte en situación y darte una definición del tema que hoy nos ocupa.
¿Qué es el contenido duplicado?
El contenido duplicado en SEO se produce cuando el texto se replica parcial o totalmente en diferentes URLs, ya sean en páginas dentro de un mismo dominio (interno) o en páginas de otros sitios Web diferentes (externo).
Además, este problema también puede suceder porque 2 o más URLs conducen a la misma página dentro de tu dominio Web.
En la mayoría de los casos, las réplicas externas ocurren debido a la copia o el plagio de terceros.
Por el contrario, el contenido duplicado interno suele producirse por errores en la estructura Web de nuestro sitio, y ellos hacen que varias URLs conduzcan a la misma página, o porque hemos utilizado gran parte de un texto en las descripciones de 2 o más páginas.
Se estima que el contenido se puede considerar como duplicado, cuando más del 30% del mismo ya se encuentra literalmente publicado en otras URLs.
En sentido inverso, se podría considerar original cuando al menos el 70% del texto que contiene una página no tiene una estructura literalmente idéntica a la de otras.
¿Puedo ser penalizado por el contenido duplicado?
Según mi experiencia, tanto la duplicación del contenido como la canibalización de palabras clave, en la mayoría de los casos, en lugar de acarrearnos una penalización pura y dura, lo que hace es reducir la calidad de nuestras páginas de cara Google y por ello, las mismas tienen una gran pérdida de posiciones en la SERP.
Por supuesto que, si tu posees un sitio Web que abusa continuamente de estas prácticas, muy probablemente mo será penalizado por Panda (el algoritmo de Google para controlar estos temas).
De todos modos, penalice o no, deberías tener en claro que los motores de búsqueda no ven con buenos ojos estas cosas. Además, el gran progreso en sus algoritmos, les permite detectar más fácilmente estas copias de textos (sobre todo dentro de una misma Web).

¿Por qué es tan negativo para mi Web el contenido duplicado?
Teniendo en cuenta que ya eres consciente de qué estamos hablamos y a qué me refiero con este problema SEO tan común, debes saber que algunas de las consecuencias que te puede ocasionar son las siguientes:
► Tener contenido de baja calidad
Este problema puede bajar la calidad de tus páginas de cara a los usuarios y a Google.
Esto quiere decir que la que Google seleccione, puede que no sea la que tú deseas y, como consecuencia de esto, se puede mostrar una “copia” con menor calidad a los usuarios y que se posicionaría peor.
► Descenso de la visibilidad orgánica
En definitiva, si pierdes calidad, también pierdes posiciones con tus páginas. Y esta bajada en los resultados de la SERP, acarrea una merma de tu visibilidad Online y tráfico proveniente de los buscadores.
► Descenso de las conversiones
Si tienes diferentes páginas con un texto muy similar, el buscador deberá seleccionar por el mismo la página más óptima para esa intención de búsqueda.
Pudiendo ser la elegida una que no sea la mas conveniente para la estrategia de tu negocio.
► Atribución de autoría equivocada
Cuando detecta dos URLs similares en diferentes dominios, el buscador escoge la versión original en base a la fecha de indexación y/o a la popularidad del sitio.
Es decir, Google podría decidir erróneamente cuál es el original y, sobre todo si tienes poca autoridad en Internet, castigar al sitio Web equivocado.
Si tú actúas siempre con profesionalidad y generas tus propios textos, comprendo que esto te produzca, cuanto menos, indignación.
Por eso es tan importante rastrear internet con cierta frecuencia, para detectar copias de tu contenido original, ya que el perjudicado puedes llegar a ser injustamente tú.
► Perdida de autoridad
Al igual que con la canibalización, las páginas duplicadas pueden hacer que tus contenidos tengan menos fuerza.
Pero, además, los enlaces que recibes pueden apuntar a distintas URLs para una misma temática, y en vez de sumar fuerzas para potenciar su posicionamiento, se están dividiendo los enlaces que recibes.
► Problemas en la Indexación
La indexación de las páginas se puede ver afectada, porque el buscador rastrea todas ellas durante una cantidad de tiempo determinada (Crawl Budget).
La pérdida de tiempo en este rastreo, por un exceso de páginas de baja calidad o duplicadas, hará que el buscador deje parte de tu sitio sin visitar.
10 Herramientas para saber si tengo contenido duplicado en mi sitio Web
 |
Para analizar las duplicidades, lo más sensato es comenzar por los títulos, encabezados, descripciones y secciones similares. Los métodos más efectivos para identificarlo es mediante el uso de herramientas.
Y cuando digo a herramientas, no sólo me refiero a disntintos tipos de plataformas o software creado para ello, sino que además hablo de métodos de búsqueda, como el “site:”, del que te hablaré más adelante:
1. Google Search Console
Es uno de los mejores puntos de partida. Para analizar ésta y otras cuestiones relativas a tu propio dominio en Internet, date de alta en las herramientas para webmasters de Google y accede a “Aspectos de búsqueda” y “Mejoras en HTML”.
A continuación, observa las etiquetas de títulos y metadescripciones duplicadas. Encontrarás las réplicas existentes y las páginas para que las puedas corregir.
Sin duda, acudir a Google Search Console es una buena opción para detectar si dentro de tu Web tienes contenidos duplicados.
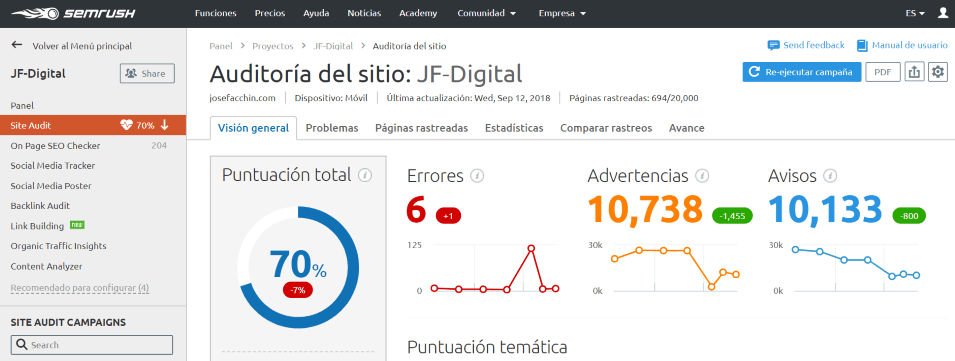
2. SEMrush
Como sabes, SEMrush además de ser una de mis herramientas favoritas, además es también una de las más completas y, como tal, incluye una forma de detectar si tienes algún problema de este tipo.
Dispone de una herramienta muy completa de “Auditoría SEO” de un sitio Web, donde se puede identificar el contenido duplicado con facilidad.
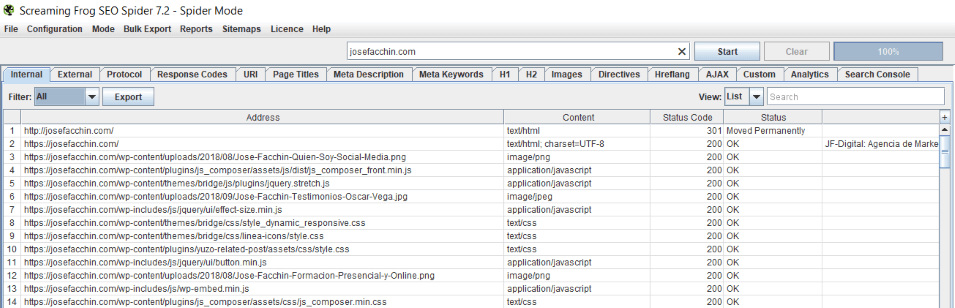
3. Screaming Frog
Gracias a Screaming Frog, se puede rastrear un sitio en búsqueda de duplicidades, entre otras funcionalidades que te permite esta potente herramienta SEO. Para ello has de utilizar el filtro “duplicate” en las pestañas Page, URL, H1 y Meta Description.
Debo advertirte que no es una herramienta gratuita, sin embargo, sus grandes funcionalidades pueden hacerte plantear la idea de contratarla. Estamos hablando de algo así como 160€ al año.
4. Google Analytics
Si accedes al informe “Comportamiento“, “Contenido del sitio” y “Páginas de destino“, puedes encontrar también duplicidades. Aquí, Google Analytics, buscan páginas y URL’s que reciben un tráfico orgánico menor del que le correspondería.
5. Plagiarisma
Gracias a la herramienta Online Plagiarisma puedes identificar si un texto es original o coincide con alguno ya publicado en la red, simplemente incluyendo éste en el espacio habilitado para ello.
Además, puedes subir tu fichero PDF desde Google Drive cómodamente, si es que guardas tus posts en la nube, previamente a publicarlos en tu blog.
Personalmente, tengo predilección por ella, dada su rapidez y sencillez para informarte de si el contenido elegido es copiado de otro que ya existe en Internet. De hecho, es una de las herramientas de comprobación que uso junto a mi equipo en JF-Digital.
También puedes descargarlo e instalarlo en tu disco duro, si así lo prefieres.
6. Quetext
Se trata de una simple e intuitiva plataforma Online que, una vez pegues en el espacio habilitado para ello el trozo de texto en cuestión, te da toda la información necesaria para saber si éste es copiado u original.
Con Quetext puedes conocer exactamente qué otros sitios Web son los que ya tienen publicado un texto idéntico al que le has indicado a la herramienta, marcándote así los fragmentos exactos que, por tanto, no deberías publicar en tu página, si no quieres ser penalizado.

Existe una gran cantidad de herramientas de análisis Web para identificar los enlaces rotos, las páginas no indexadas y las duplicidades, además de otros problemas que son más complicados de detectar.
Estas herramientas las veremos más adelante y son Siteliner o SEMrush entre otras.
7. CopyScape

Además de ser una de mis favoritas, es muy usada por gran cantidad de profesionales del Marketing Digital e Internet en general.
Con CopyScape puedes introducir la URL de tu site y comprobar si existe algún otro contenido en la red idéntico al tuyo. De esta manera, podrías contactar con el responsable y pedirle explicaicones por ello.
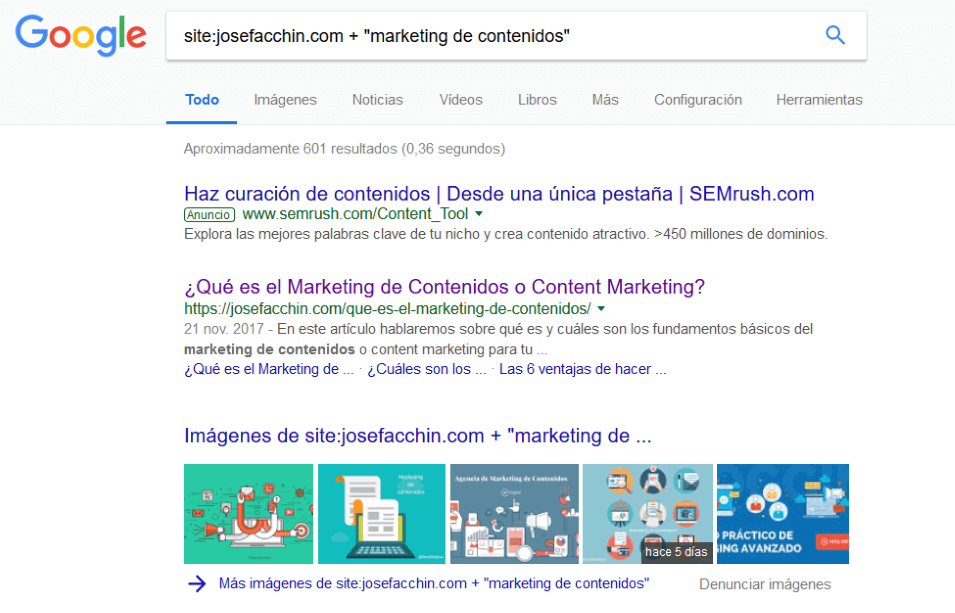
8. Comando “site:” + “Keyword” en Google
Este comando busca en Google, páginas indexadas de tu sitio Web con una determinada frase o palabra clave en concreto (o productos si hablamos de una tienda online).
Por ejemplo, entre los resultados, se puede comprobar si hay páginas indexadas en Google con descripciones o títulos duplicados y si algunas de ellas se han trasladado al índice secundario. Al mismo tiempo, este también es un método genial para encontrar canibalizaciones SEO.
9. Virante Tools
Es muy efectiva para detectar aspectos básicos que debe cumplir un blog para no tener duplicidad en él.
Lo ideal es tener todos los “check” en verde y, en caso de encontrar alguno en rojo, será donde debamos trabajar para poder llegar a subsanar el error.
Si en Virante Tools el primer check está en rojo querrá decir que la URL no es canónica y que el formato de URL no está bien seleccionado. Este es el mayor error con el que generar este problema que hoy nos ocupa.

10. SiteLiner
Con esta herramienta Online podrás detectar el contenido duplicado de un sitio Web pequeño. Con su versión gratuita se pueden analizar hasta un máximo de 250 páginas.
Por ende, aunque sea para empezar, con SiteLiner tienes suficiente.
¿Cómo puedo eliminar el contenido duplicado en mi blog o sitio Web?
Ya ha quedado claro que a los buscadores no les gusta la duplicidad, porque empobrece la experiencia de los usuarios. Por tanto, si lo detectas, debes hacer “lo imposible” para eliminarlo.
Si éste lo has duplicado tú mismo en tu propio sitio, hay varias formas de solucionarlo o de asegurarte de que los buscadores sepan cuál es el que quieres que tome como “principal”.
El problema es que hay que saber algo de programación y no todo el mundo está en situación de escribir códigos en los lugares correctos de la Web.
Si no dominas el lenguaje HTML, mi consejo es que busques la ayuda de un especialista o que contrates sus servicios.
A estas alturas del artículo, ya debes ser consciente de la importancia de no tener contenido duplicado si quieres que tu Web no sea delegada a los puestos (o páginas) más retrasados de la SERP de Google.
Las formas más habituales de tratar duplicidades en nuestra Web son:
1. Cambia el texto
Esta es una de las maneras más sencillas, pero a su vez menos utilizadas. Por ello, si tienes dos páginas muy similares, y quieres posicionar ambas en los buscadores, opta por redactar nuevamente el contenido de una de esas URLs para que sea lo más original posible.
2. Hacer un “Canonical”
La etiqueta “rel=canonical” se creó para tratar justamente esta situación. Por ejemplo, ella es muy utilizada en un eCommerce cuando tenemos productos con descripciones muy similares.
El “rel=canonical”, es una línea de código que se inserta en el <head> del código de tu página e indica a los buscadores cual es la versión Original de ella. Y, por tanto, evita que éstos cataloguen como duplicados esos contenidos.
Aquí, debemos tener en cuenta que, con este atributo, son los buscadores los que toman la decisión final de qué hacer con esas páginas, es decir, ellos resuelven si las indexan a todas o solo a la principal (o canonical).
Esta es una solución que cualquiera puede poner en práctica. Pero, también es cierto que se necesita tener ciertos conocimientos de HTML para colocar la etiqueta en el sitio correcto o disponer de un plugin/modulo que te ayude con ese trabajo.
3. Redirección 301
Es la mejor opción cuando no es viable utilizar la etiqueta anterior o cuando tienes dos URLs indexadas que conducen al mismo lugar.
Con la Redirección 301 directamente se envía a los visitantes de una página a otra que nos interese de manera automática.
Es decir, puedes utilizarla principalmente en dos situaciones:
1º Si tienes dos páginas con contenido idéntico o extremadamente similar, y por las razones que sean no puedes utilizar un canonical, entonces deberías redirigir una hacia la otra (teniendo en cuenta su relevancia o importancia, ya que una de ellas desaparecería de cara a tus visitantes).
2º Los visitantes de tu sitio Web pueden llegar a una misma página de destino desde diferentes URLs. Haciendo una redirección 301 de todas esas URLs hacia la principal o correcta, vengan de donde vengan, diriges a tus visitantes y a los buscadores a una solo URL.
Y, de paso, informamos a los buscadores cual es la URL “correcta” que deben indexar para ese contenido.
4. Robots.txt
Es otra de las acciones para evitar la duplicidad en las páginas.
Si, por cualquier motivo, no puedes redirigir o borrar la página con contenido duplicado, ésta es la mejor opción para evitar las temidas sanciones.
Con los archivos Robots.txt le decimos a los buscadores qué páginas o archivos debe ignorar o bloquear y, por tanto, no deben invertir ni un sólo milisegundo en ella.
4. Mediante parámetros de URL’s
Si el contenido duplicado se produce por ciertos parámetros, desde ‘rastreo’ y ‘parámetros de URL’, puedes indicar a Google qué debe ignorar mediante Search Console (Webmaster Tools).
El procedimiento es casi el mismo que con Robots.txt: se le indica a los buscadores qué URL’s indexar y cuáles debe ignorar.
Este método es muy útil sobre todo para eCommerce con diferentes tallas y colores de un mismo producto. La URL será la misma para todas las variables de tallas y colores, pero al webmaster sólo le interesará destacar una de ellas, con la descripción general del producto.
5. Único editor
Si tu blog lo editas tú mismo, estás generando información duplicada sin que tú lo sepas, a través de las páginas de autor. En WordPress, suelen ser del tipo:
https://dominio.com/author/tu-nombre
La solución es muy sencilla, debes marcar las pa´ginas de autor como “noindex – follow” y así le dices al buscador que no indexe esas URLs.
Esto solo hay que hacerlo cuando hay un único autor. Aún así, en blogs o revistas digitales donde exista una variedad de autores, tampoco estaría de más que lo hicieras.
6. No abusar de las etiquetas o las categorías en los blogs
Las categorías y las etiquetas mal utilizadas pueden ser muy peligrosas para tu posicionamiento SEO.
Por ejemplo, en un blog común, al contrario de lo que puedas estar pensando, indexar este tipo de cosas solo sirve para generar contenido duplicado o canibalizciones.
Aún así, si quieres indexar las categorías y/o las etiquetas de tu blog, hazlo de manera estratégica, con mucho cuidado y no generes cantidades industriales de ellas sin ningún tipo de coherencia o sentido.
Insisto, si no lo tienes claro, lo que puedes hacer es añadir “meta-etiquetas: noindex, follow“ entre las opciones de tu plugin SEO (si normalmente usas WordPress) y así no crearás contenido duplicado con ellas.
¿Cómo solucionar el contenido duplicado cuando está fuera de tu sitio?

Después de revisar todas las formas que existen para detectar contenido duplicado en nuestra propia Web y las distintas formas de solucionar ese problema.
Vamos a ver ahora qué podemos hacer cuando el contenido duplicado está en un dominio ajeno.
1ª Opción: petición de que elimine el contenido
En este caso, puedes solicitar “amablemente” que lo eliminen, vía correo electrónico, redes sociales o mediante un formulario de contacto.
Quízas, la persona que te plagió, no sepa lo malo que puede ser eso para los dos.
Si este primer contacto no obtiene sus frutos, algo que por desgracia ocurre con cierta frecuencia, tenemos que dar un segundo paso.
2ª Opción: un enlace canonical
Aunque lo veo difícil de conseguir, si no quieren eliminarlo, puedes pedir que enlacen a tu texto con un “canonical“.
Y, de esta forma, el buscador encontrará el contenido original y ninguno de los dos correrá el riesgo de ser penalizado.
3ª Opción: petición formal a Google
Pero puede que esta 2º opción tampoco funcione, cosa que también sucede con frecuencia.
Entonces, pasaremos a “palabras mayores”: solicitar a Google la desindexación de su URL.
Para ello, deberás presentar una solicitud según la legislación estadounidense de protección de los derechos de autor.
En todos estos casos es conveniente guardar todo el esfuerzo realizado con anterioridad para solucionar el problema por tus propios medios.
Guarda copia de los correos o los mensajes que has mandado/recibido con el Webmaster del sitio con tu contenido duplicado.
4ª Opción: la justicia ordinaria
La última opción que te queda si todo lo demás no funciona, es recurrir a la justicia ordinaria de tu país, de manera que apliquen la legislación vigente.
Deberás presentar una denuncia por un delito de plagio. Ya que publicar textos Online, no difiere en nada a si publicas textos en papel.
Todo lo que haces de manera digital tiene automáticamente derechos de autor y, por tanto, puedes recurrir a la justicia para que sea un juez el que condene al plagiador a borrar el contenido plagiado.
Y, de paso, que te compense económicamente por los daños causados, si procede.
Puede que este último método te parezca demasiado extremo, pero tienes que tener en cuenta que hay mucha gente que se gana la vida con su Web o blog (como es mi caso).
Las visitas que le llegan contratan sus servicios, compran sus productos o, simplemente, pinchan en los anuncios.
El contenido duplicado en este tipo de sitios puede bajarles los ingresos de manera considerable.

Conclusiones
Para terminar, te voy a dar unos pequeños consejos generales que te ayudarán a prevenir este problema:
El primer consejo es básico y seguramente ya lo estés pensando tú mismo: el texto de tus páginas ha de ser único en cada una de ellas.
Ten cuidado con las URLs que se generan de manera automática y que pueden llevarte a una misma página.
No utilizar nunca el mismo título o la misma descripción en páginas diferentes.
Aunque trates el mismo tema, debes dar otro punto de vista, y tratar subtemáticas diferentes a las ya publicadas previamente.
Incluye sólo la versión canónica de cualquier página en tu sitemap.
Si necesitas copiar una cita, procura de que ella sea una pequeña parte de todo tu texto.
Si, por el motivo que sea, vas a tener páginas muy similares, solo deja que el buscador tenga acceso a una sola mediante “robots” o utiliza la etiqueta “Canonical”.
Dedica al menos una hora a la semana para identificar y eliminar posibles enlaces rotos (externos o internos), así como para solucionar todas las duplicaciones que encuentres.
De todas formas, no te obsesiones, porque es prácticamente imposible reducirlo a “cero”. Lo habitual es que un sitio Web tengan alrededor de un 10% o 15% de este contenido duplicado.
Eso sí, que nunca este en tus principales páginas. Esas que influyen radicalmente en tu visibilidad y en el resultado de tus estrategias.